
机器学习及深度学习工具
发布时间:2016-01-21 栏目:软件、框架及系统 评论:0 Comments
最开始的改进是使用GPU来加速训练,GPU可以看成一种SIMT的架构,和SIMD有些类似,但是执行相同指令的warp里的32个core可 以有不同的代码路径。对于反向传播算法来说,基本计算就是矩阵向量乘法,对一个向量应用激活函数这样的向量化指令,而不像在传统的代码里会有很多if- else这样的逻辑判断,所以使用GPU加速非常有用。
但即使这样,单机的计算能力还是相对有限的。
深度学习开源工具
从数学上来讲,深度神经网络其实不复杂,我们定义不同的网络结构,比如层次之间怎么连接,每层有多少神经元,每层的激活函数是什么。前向算法非常简单,根据网络的定义计算就好了。
而反向传播算法就比较复杂了,所以现在有很多深度学习的开源框架来帮助我们把深度学习用到实际的系统中。
目前主要的开源工具有:
1. TensorFlow (from Goolge):https://www.tensorflow.org/
2. Facebook人工智能研究院(FAIR)宣布开源了一组深度学习工具,这些工具主要是针对Torch机器学习框架的插件,包括iTorch、fbcunn、fbnn、fbcuda和fblualib。这些插件能够在很大程度上提升神经网络的性能,并可用于计算机视觉和自然语言处理(NLP)等场景。目前,Torch已被Google、Twitter、Intel、AMD、NVIDIA等公司采用。
3. Facebook开源人工智能硬件平台:BigSur
4. 微软的Azure机器学习平台
5. 微软的机器学习开源工具包DMTK。其中包括了在多台服务器上展开训练的模块框架、一个主题建模算法、一个进行自然语言处理的文字嵌入算法。借助这些工具,开发者可以使用较少的服务器部署大规模的机器学习。
6. IBM的商业化神经仿生芯片TureNorth
7. IBM的开源机器学习系统SystemML。使用java语言编写,可支持描述性分析、分类、聚类、回归、矩阵分解及生存分析等算法。
8. 亚马逊机器学习平台。
此外,还有非营利性组织OpenAI(https://openai.com/blog/introducing-openai/)也值得关注。
Google收购的子公司DeepMind:http://deepmind.com/
我们可以从以下几个不同的角度来分类这些开源的深度学习框架。
-
通用vs专用
深度学习抽象到最后都是一个数学模型,相对于传统的机器学习方法来说少了很多特征抽取的工作,但是要把它用到实际的系统中还有很多事情要做。而且对于很多系统来说,深度学习只是其中的一个模块。
拿语音识别来说,语音识别包含很多模块,比如声学模型和语言模型,现在的声学模型可以用LSTMs(一种RNN,也是一种深度学习网络)来做, 但是我们需要把它融入整个系统,这就有很多工作需要做。而且目前大部分的机器学习方法包括深度学习,都必须假设训练数据和测试数据是相同(或者类似)的分 布的。所以在实际的应用中,我们需要做很多数据相关的预处理工作。
比如Kaldi,它是一个语音识别的工具,实现了语音识别的所有模块,也包括一些语音识别常用的深度神经网络模型,比如DNN和LSTM。
而Caffe更多的是用在图像识别,它实现了CNN,因为这个模型在图像识别上效果非常好。
-
框架vs库
大部分开源的深度学习工具把整个模型都封装好了,我们只需要指定一些参数就行了。 比如我们使用Caffe的CNN。
但是还有一些工具只是提供一些基础库,比如Theano,它提供了自动求梯度的工具。
我们可以自己定义网络的结构,我们不需要自己求梯度。使用Theano的好处是如果我们“创造”一个新的网络结构或者是很新的深度神经网络,那么 其它框架很可能还没有实现,所以Theano在学术界很流行。当然坏处就是因为它不可能针对特定的模型做优化,所以可能性能不如特定的实现那么好。
-
单机vs集群
目前大部分的开源工具都是单机版的,有些支持在一个节点的多个GPU训练,但是支持GPU cluster比较少,目前支持多机训练的有GraphLab和Deeplearning4j。
Tensor Flow到底是什么?
Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow即为张量从图的一端流动到另一端。
TensorFlow 表达了高层次的机器学习计算,大幅简化了第一代系统,并且具备更好的灵活性和可延展性。 TensorFlow一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型,从电话、单个CPU / GPU到成百上千GPU卡组成的分布式系统。

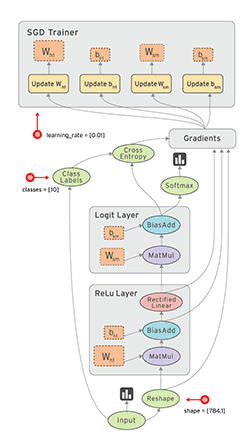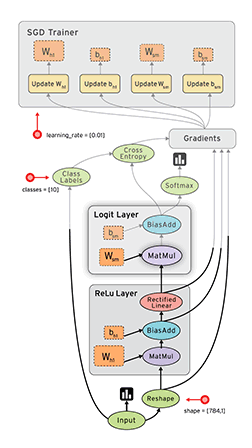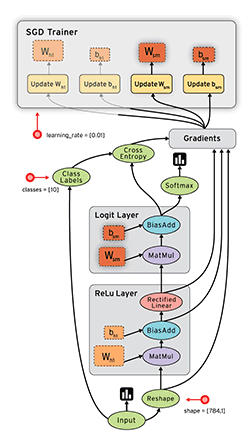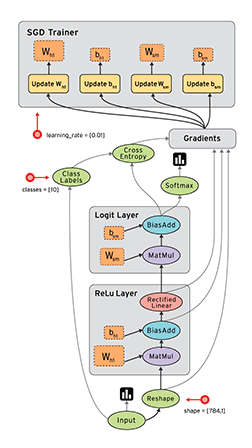
从目前的文档看,TensorFlow支持CNN、RNN和LSTM算法,这都是目前在Image,Speech和NLP最流行的深度神经网络模型。
而且从Jeff Dean的论文来看,它肯定是支持集群上的训练的。
在论文里的例子来看,这个架构有点像Spark或者Dryad等图计算模型。就像写Map-reduce代码一样,我们从高层的角度来定义我们的 业务逻辑,然后这个架构帮我们调度和分配计算资源(甚至容错,比如某个计算节点挂了或者太慢)。目前开源的实现分布式Deep learning的 GraphLab就是GAS的架构,我们必须按照它的抽象来编写Deep Learing代码(或者其它分布式代码,如果PageRank),而 Deeplearning4j直接使用了Spark。
Map-Reduce的思想非常简单,但是要写出一个稳定可用的工业级产品来就不容易了。而支持分布式机器学习尤其是深度学习的产品就更难 了,Google的TensorFlow应该是一种抽象方式,可惜现在开源的部分并没有这些内容。有点像Google开源了一个单机版的Hadoop,可 以用这种抽象(Map-reduce)来简化大数据编程,但是实际应用肯定就大大受限制了。
深度学习能解决所有问题吗?
至少目前来看,深度学习只是在Speech和Image这种比较“浅层”的智能问题上效果是比较明显的,而对于语言理解和推理这些问题效果就不那么好了,也许未来的深度神经网络能解决更“智能”的问题,但只是目前还不行。
Google开源TensorFlow的意义
这一次的Google开源深度学习系统TensorFlow在很多地方可以应用,如语音识别,自然语言理解,计算机视觉,广告等等。但是,基于以上论点,我们也不能过分夸大TensorFlow这种通用深度学习框架在一个工业界机器学习系统里的作用。 在一个完整的工业界语音识别系统里, 除了深度学习算法外,还有很多工作是专业领域相关的算法,以及海量数据收集和工程系统架构的搭建。
不过总的来说,这次谷歌的开源很有意义,尤其是对于中国的很多创业公司来说,他们大都没有能力理解并开发一个与国际同步的深度学习系统,所以TensorFlow会大大降低深度学习在各个行业中的应用难度。
留下评论
You must be logged in to post a comment.





