
SqueezeNet
发布时间:2020-11-23 栏目:人工智能, 图像处理, 深度学习 评论:0 Comments
SqueezeNet 发表于ICLR-2017,作者分别来自Berkeley和Stanford,SqueezeNet不是模型压缩技术,而是 “design strategies for CNN architectures with few parameters”
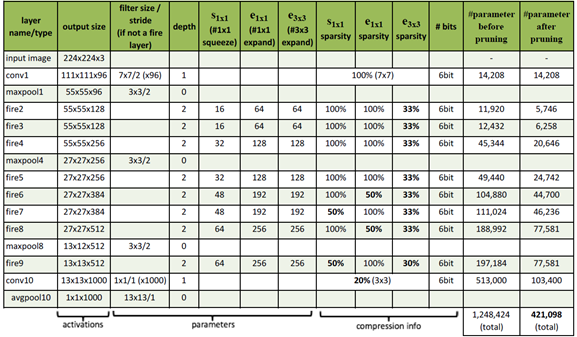
SqueezeNet的模型压缩使用了3个策略:
- 将
卷积替换成
卷积:通过这一步,一个卷积操作的参数数量减少了9倍;
- 减少
(其中
,
分别是输入Feature Map和输出Feature Map的通道数),作者任务这样一个计算量过于庞大,因此希望将
- 将降采样后置:作者认为较大的Feature Map含有更多的信息,因此将降采样往分类层移动。注意这样的操作虽然会提升网络的精度,但是它有一个非常严重的缺点:即会增加网络的计算量。
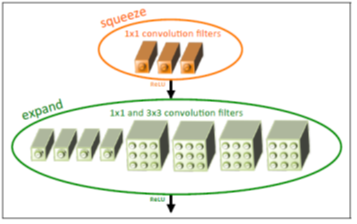
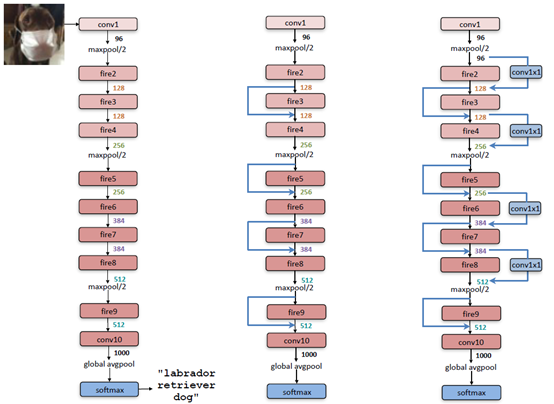
SqueezeNet的核心在于Fire module,Fire module 由两层构成,分别是squeeze层+expand层,如下图所示,squeeze层是一个1*1卷积核的卷积层,expand层是1*1 和3*3卷积核的卷积层,expand层中,把1*1 和3*3 得到的feature map 进行concat,具体操作如下图2所示
下面说一下SqueezeNet的一些具体的实现细节:
(1)在Fire模块中,expand层采用了混合卷积核1×1和3×3,其stride均为1,对于1×1卷积核,其输出feature map与原始一样大小,但是由于它要和3×3得到的feature map做concat,所以3×3卷积进行了padding=1的操作,实现的话就设置padding=”same”;
(2)Fire模块中所有卷积层的激活函数采用ReLU;
(3)Fire9层后采用了dropout,其中keep_prob=0.5;
(4)SqueezeNet没有全连接层,而是采用了全局的avgpool层,即pool size与输入feature map大小一致;
(5)训练采用线性递减的学习速率,初始学习速率为0.04。
参考:
https://zhuanlan.zhihu.com/p/49465950
https://blog.csdn.net/u011995719/article/details/78908755
https://zhuanlan.zhihu.com/p/31558773





